

-
Getting Started (38)

-
Troubleshooting (19)
-
Open Stack (15)
- How to Launch an Instance from a Volume
- Importing a VHD image that uses linux volume management for its root directory
- OpenStack Network Concepts
- Creating an Instance with a Specific Fixed IP
- OpenStack Mitaka CLI Notes
- Why Choose OpenStack?
- OpenStack Storage Concepts
- Ursula and OpenStack
- How to Create An Instance With Static IP
- Quotas
- How to Isolate Tenants (Projects)
- External reference materials
- View More ( 3 )
User Docs
-
Horizon [GUI] (10)
-
Nova [Compute] (13)
-
Neutron [Networking] (22)
-
Glance [Images] (6)
-
Cinder [Block Storage] (13)
-
Keystone [Identity] (8)
-
Heat [Orchestration] (7)
-
Ceilometer [Telemetry] (1)
Building Up to OpenStack II -- Improving Cloud Performance
Republished from https://admin.blogs.prd.ibm.event.ibm.com/blogs/bluemix/2016/11/building-openstack-ii-improving-cloud-performance/
In this article, second in the series, we’ll cover more cloud fundamentals: More about QEMU, and lots more about how to improve your cloud’s overall workload performance.
Essentially, improving performance for your cloud requires creating I/O efficiency improvements when accessing network and storage devices. By optimizing I/O virtualization so that the I/O device interfaces between the guest VMs and the host are more efficient, you can improve performance and add flexibility for I/O. Thus, your cloud’s performance improves overall because more of the total processor capabilities are available to your workload.
It’s all about improving I/O performance through virtualization
Remember that QEMU is the basic element of a cloud VM. It gets the job done! However, because QEMU is an emulator, it makes sense to rely on it as little as possible when speed is of the essence. Although KVM adds some processor and memory performance improvement to QEMU, a bottleneck remains for I/O performance.
There are two paths for improving I/O performance with virtualization: a software path and a hardware path. We’ll examine each path in this blog. Along each path, each step we travel takes QEMU further out of the action. Why? Less emulation means better performance.
The software path involves virtualizing the “traditional” devices and their drivers more efficiently. The hardware path involves linking devices more directly to the VMs, and possibly even using specialized hardware that implements a feature called Single Root IO Virtualization (SR-IOV). That’s essentially a hardware-assisted path for rapidly pairing up VMs with virtualized devices that can be instantiated as needed.
The Software Path: QEMU, ‘virtio,’ and ‘vhost’
As we covered in a previous blog, QEMU was designed to operate as an emulator, which can even emulate historic operating systems such as Windows NT and OS/2. It emulates whatever hardware the operating system expects to find; therefore, the default devices it exposes are “common” physical hardware devices. But the method that the operating system uses to communicate with these devices was not designed with virtualization in mind!
Older I/O devices typically were not general-purpose processors, and they were slower. Thus, in the old “hardware” days, there was little benefit to optimizing I/O performance. For example, physical disks take a significant amount of time (4ms) to access a location on a disk, so there would be little benefit to optimizing communications between the driver and the disk controller. In a modern cloud, with VMs as servers, significant benefits arise from improving I/O performance, and it can be accomplished in well-understood ways.
Why does I/O virtualization help?
To perform efficient I/O, your cloud system requires (1) a driver for the guest VM, (2) some additional backend in the host software (e.g. QEMU) that provides the I/O device, and finally, (3) the interfaces that the host software uses to communicate with the underlying I/O device.
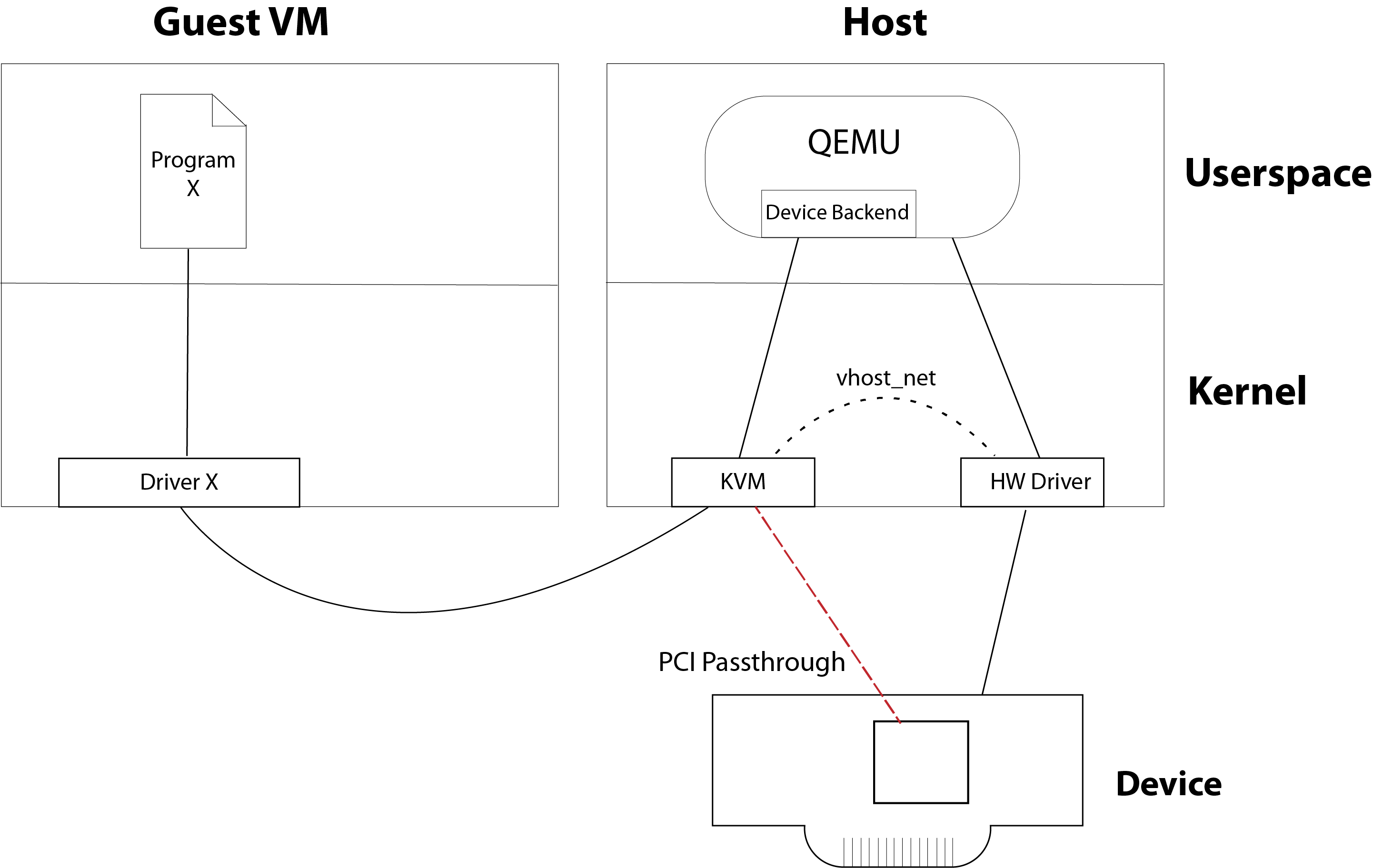
As you can see in the figure, several components get involved in fulfilling an I/O request from within a VM. Each transition between these components incurs a performance penalty. To demonstrate how quickly the I/O performance can degrade, here’s a step-by-step breakdown of how it works:
-
First, the program running within the VM makes its I/O request to the operating system of the VM, using the “normal” interface. (If software running on a VM used a different method, virtualization would not be transparent to the user.)
-
Next, the VM’s operating system uses the driver corresponding to the device exposed by QEMU.
-
The driver then performs some operation, which is trapped by KVM and handed off for QEMU to fulfill.
-
QEMU then uses a similar interface to make an I/O request to the host operating system.
-
The host operating system then uses driver corresponding the physical hardware to perform the requested I/O operation.
How can we speed this process up? Two good options exist. First, we could more efficiently virtualize the way we emulate any particular device. That option is generally referred to as “paravirtualized drivers,” and the best example of that is something called virtio, which has been incorporated into OpenStack Nova. Second, for further performance improvements, we can eliminate another transition by removing device emulation from the VM completely. That is, we take QEMU’s “device emulation” out of the guest VM, and limit it to the host operating system.
Optimization 1: Paravirtualized drivers: The virtio approach
Virtio is a family of virtualized devices that are exposed by QEMU, along with their corresponding drivers, within a VM’s operating system. These drivers optimize the interface between the guest VM driver and QEMU by using modern, efficient data structures, such as ring buffers, rather than slavishly emulating the interface of an existing hardware device. Using virtio, the VM communicates more efficiently with QEMU, thereby improving I/O performance.
As a caveat, virtio requires guest VM images to include these faster virtio drivers, so some older images (e.g. Windows 95 or 98) may not work with virtio. Fortunately, most operating systems now include virtio drivers by default, and they have done so since about 2013.
Optimization 2: Vhost (Removing the QEMU userspace device model)
The next performance optimization consists of moving the virtio device emulation capability out of the VM altogether, and into the host operating system kernel. This move avoids the performance penalty associated with the transitions from KVM to QEMU and back to the host kernel.
The Hardware Path: PCI passthrough and SR-IOV
PCI passthrough is a generic mechanism that can apply to any PCI device. It offers an alternative to the types of software virtualization of devices and drivers that we described in the previous sections. In contrast to virtio and vhost, PCI passthrough exposes a hardware I/O device directly to the guest VM, thereby removing QEMU and the host kernel from the I/O path altogether, and eliminating the performance penalties of these software-emulation transitions.
PCI passthrough is a good alternative for creating improved performance in many use cases.
-
For example, some people use this passthrough technique for gaming, by setting up PCI passthrough for their video card. Note that in this case, virtualization isn’t used to improve gaming performance, but to run games for other Operating Systems. Virtualization of modern games isn’t really viable without PCI passthrough.
-
Probably the most common type of PCI passthrough device is the network card. For example, you can do network card passthrough with vhost_net, which gets rid of QEMU from the network data path, but vhost_net still relies on the host kernel’s intact network stack.
-
It’s worth noting that PCI passthrough generally is impractical for host bus adapters (HBA) and disks, because most servers only have a single disk controller that is connected to all the disks on the server. Thus, the capacity of those disks could not be shared among the VMs in a cloud; all the disks would belong to a single VM. The next section tells how HBAs that are enabled with SR-IOV have created solutions for this difficulty.
-
One might imagine an esoteric application of PCI passthrough for an HBA, wherein a cloud can be booted from USB, and then all of the disk storage capacity allocated to a single VM that performs as a backend database.
It’s important to remember that PCI passthrough requires a dedicated I/O device for each guest VM. This requirement to have dedicated hardware for each VM reduces the flexibility that comes from virtualization, and it significantly increases cost. Luckily, some newer types of hardware are available, which can mitigate cost through built-in, hardware-assisted presentation of virtualized PCI devices. It’s a technique called SR-IOV.
SR-IOV
Newer, high-end network interfaces and disk controllers include SR-IOV (single root I/O virtualization). Essentially, these hardware devices can present themselves as multiple PCI devices, each of which can be attached to a VM. In a typical deployment, there would be a main one, a parent (or PF), and then one or more logical devices known as virtual function units (VFs). By configuring the PF, additional VF devices can be created along with their associated resources. Then, these VFs can be attached to individual VMs by means of PCI passthrough.
Potentially, you could use PCI passthrough for two I/O devices per guest VM: a network interface and disk controller. For example, with two SR-IOV devices, you could gain I/O performance improvement both for network and for storage.
Summary
You can improve your cloud’s workload performance by using either path we’ve described in this article, the software path or the hardware path. There’s an optimized software path with virtio and vhost, and a hardware-assisted optimized path that uses PCI passthrough and SR-IOV.
Further reading on this topic:
Red Hat Enterprise Linux 7 Virtualization Tuning and Optimization Guide